
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Rocky Linux
- colab
- ICT멘토링
- Resnet
- 크롤링 개발
- rnn
- 고등학생 대상
- GoogleDrive
- 국가과제
- API
- 코딩도장
- git
- Web
- Github
- OSS
- Spring Boot
- 인터넷의이해
- C언어
- Spring
- Docker
- KAKAO
- LINUX MASTER
- VSCode
- Machine Learning
- Python
- Database
- ChatGPT
- suricata
- Powershell
- cloud
- Today
- Total
빈 칸의 포트폴리오
[실기] 2장. 데이터 입출력 구현 본문

029(B) 데이터베이스 개요
DBMS: 사용자의 요구에 따라 정보를 생성해주고, DB를 관리해주는 SW
(필수 기능 3가지 - 정의, 조작, 제어)
스키마: DB의 구조와 제약조건에 관한 전반적인 명세를 기술한 것
| 외부 스키마 | 사용자나 응용 프로그래머가 각 개인의 입장에서 필요로 하는 DB의 논리적 구조를 정의한 것 |
| 개념 스키마 | DB의 전체적인 논리적 구조 모든 응용 프로그램이나 사용자들이 필요로 하는 데이터를 종합한 조직 전체의 DB로, 하나만 존재 |
| 내부 스키마 | 물리적 저장장치의 입장에서 본 DB 구조 실제로 저장될 레코드의 형식, 저장 데이터 항목의 표현 방법, 내부 레코드의 물리적 순서 등을 나타냄 |
030(A) 데이터베이스 설계
DB 설계 순서
1. 요구 조건 분석: 요구 조건 명세서 작성
2. 개념적 설계: 개념 스키마, 트랜잭션 모델링, E-R 모델
3. 논리적 설계: 목표 DBMS에 맞는 논리 스키마 설계, 트랜잭션 인터페이스 설계
4. 물리적 설계: 목표 DBMS에 맞는 물리적 구조의 데이터로 변환
5. 구현: 목표 DBMS의 DDL(데이터 정의어)로 DB 생성, 트랜잭션 작성
개념적 설계(정보 모델링, 개념화) : 현실 세계에 대한 인식을 추상화 개념으로 표현하는 과정
논리적 설계(데이터 모델링): 현실 세계에서 바랭하는 자료를 특정 DBMS가 지원하는 논리적 자료 구조로 변환시키는 과정
물리적 설계(데이터 구조화): 논리적 구조로 표현된 데이터를 물리적 구조의 데이터로 변환하는 과정
031(B) 데이터 모델의 개념
데이터 모델에 표시할 요소
| 구조(Structure) | 논리적으로 표현된 개체 타입들 간의 관계로서 데이터 구조 및 정적 성질 표현 |
| 연산(Operation) | DB에 저장된 실제 데이터를 처리하는 작업에 대한 명세로서 DB를 조작하는 기본 도구 |
| 제약 조건(Constraint) | DB에 저장될 수 있는 실제 데이터의 논리적인 제약 조건 |
032(B) 데이터 모델의 구성 요소
관계의 형태
| 일 대 일(1:1) | 개체 집합 X의 각 원소가 개체 집합 Y의 원소 한 개와 대응하는 관계 |
| 일 대 다(1:n) | 개체 집합 X의 각 원소는 개체 집합 Y의 원소 여러 개와 대응하고 있지만, 개체 집합 Y의 각 원소는 개체 집합 X의 원소 한 개와 대응하는 관계 |
| 다 대 일(n:1) | 개체 집합 X의 각 원소는 개체 집합 Y의 원소 여러 개와 대응하고, 개체 집합 Y의 각 원소도 개체 집합 X의 원소 여러 개와 대응하는 관계 |

033(B) E-R(개체-관계) 모델
E-R 다이어그램
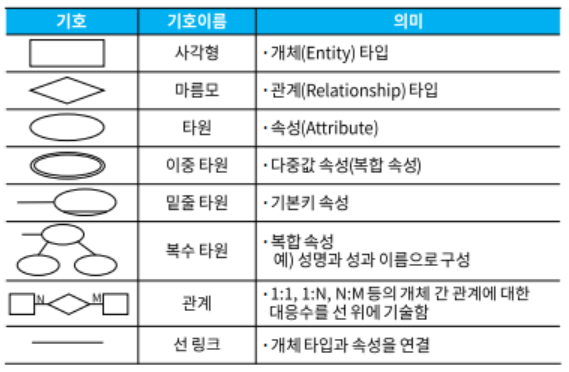
034(A) 관계형 데이터베이스의 구조 / 관계형 데이터 모델
관계형 데이터베이스의 릴레이션 구조
(릴레이션 스키마: 구조 / 릴레이션 인스턴스: 실제 값들)

튜플: 릴레이션을 구성하는 각각의 행
- 속성의 모임, 레코드, 튜플의 수: 카디널리티(기수=대응수)
속성: DB를 구성하는 가장 작은 논리적 단위
- 파일 구조상의 데이터 항목 또는 데이터 필드 / 개체의 속성을 기술 / 속성의 수:디그리(=차수)
도메인: 하나의 애트리뷰트가 취할 수 있는 같은 타입의 원자값들의 집합
('성별' 애트리뷰트의 도메인은 "남"과 "여", 그 외의 값은 입력될 수 X)
릴레이션의 특징
- 한 릴레이션에는 똑같은 튜플이 포함 X -> 릴레이션에 포함된 튜플들 모두 상이
- 튜플 사이에 순서 X
- 튜플들의 삽입, 삭제 등의 작업으로 인해 릴레이션은 시간에 따라 변함
- 속성의 며칭은 유일해야 하지만, 속성을 구성하는 값은 동일할 수 있음
- 튜플 식별을 위해 속성들의 부분집합을 키로 설정
035(A) 관계형 데이터베이스의 제약 조건 - 키(Key)
키: DB에서 조건에 만족하는 튜플을 찾거나 순서대로 정렬할 때 기준이 되는 속서
(후보키, 기본키, 대체키, 슈퍼키, 외래키)
후보키(Candidate Key): 속서을 중에서 튜플을 유일하게 식별하기 위해 사용되는 속성들의 부분집합
- 기본키로 사용할 수 있는 속성들 / 유일성과 최소성을 모두 만족해야 함
| 유일성(Unique) | 하나의 키 값으로 하나의 튜플만을 유일하게 식별할 수 있어야 함 |
| 최소성(Minimality) | 키를 구성하는 속성 하나를 제거하면 유일하게 식별할 수 없도록 꼭 필요한 최소의 속성으로 구성되어야 함 |
기본키(Primary Key): 후보키 중에서 특별히 선정된 주키
- 중복된 값을 가질 수 X / 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성 / NULL값 가질 수 X
대체키(Alternate Key): 후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키 (=보조키)
슈퍼키(Super Key): 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키
- 유일성은 만족하지만, 최소성은 만족하지 X
외래키(Foreign Key): 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합
- 한 릴레이션에 속한 속성 A와 참조 릴레이션의 기본키인 B가 동일한 도메인 상에서 정의되었을 때의 속성 A를 외래키라고 함
036(B) 관계형 데이터베이스의 제약 조건 - 무결성(Integrity)
무결성의 종류
| 개체 무결성 | 기본 테이블의 기본키를 구성하는 어떤 속성도 Null 값이나 중복값을 가질 수 없다 |
| 참조 무결성 | 외래키 값은 Null이거나 참조 릴레이션의 기본키 값과 동일해야 함. 즉 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없다 |
| 도메인 무결성 | 주어진 속성 값이 정의된 도메인에 속한 값이어야 한다는 규정 |
| 사용자 정의 무결성 | 속성 값들이 사용자가 정의한 제약조건에 만족되어야 한다는 규정 |
037(A) 관계대수 및 관계해석
관계대수: 관계형 DB에서 원하는 정보와 그 정보를 검색하기 위해서 어떻게 유도하는가를 기술하는 절차적인 언어
- 연산의 순서를 명시 / 순수 관계 연산자, 일반 집합 연산자
순수 관계 연산자
| Select | σ | 릴레이션에 존재하는 튜플 중에서 선택 조건을 만족하는 튜플의 부분집합을 구하여 새로운 릴레이션을 만드는 연산 행에 해당하는 튜플을 구하는 것이므로 수평 연산이라고도 함 |
| Project | π | 주어진 릴레이션에서 속성 리스트에 제시된 속성 값만을 추출하여 새로운 릴레이션을 만드는 연산 연산 결과에 중복 발생 시 중복 제거됨 릴레이션의 열에 해당하는 속성을 추출하는 것이므로 수직 연산자라고도 함 |
| Join | ⋈ | 공통 속성을 중심으로 두 개의 릴레이션을 하나로 합쳐서 새로운 릴레이션을 만드는 연산 Join의 결과는 카디션 프로덕트(교차곱)를 수행한 다음 Select를 수행한 것과 같음 |
| Division | ÷ | X⊃Y인 두 개의 릴레이션 R(X)와 S(Y)가 있을 때, R의 속성이 S의 속성값을 모두 가진 튜플에서 S가 가진 속성을 제외한 속성만을 구하는 연산 |
일반 집합 연산자: 수학적 집합 이론에서 사용하는 연산자
- 합집합(UNION), 교집합(INTERSECTION), 차집합(DIFFERENCE)을 처리하기 위해선 합병 조건을 만족해야 함

관계해석: 관계 데이터의 연산을 표현하는 방법 / 비절차적 특성
038(A) 이상/함수적 종속
이상(Anomaly): 테이블에서 일부 속성들의 종속으로 인해 데이터 중복이 발생하고, 이 중복으로 인해 문제가 발생하는 현상들
<수강>
| 학번 | 과목번호 | 성적 | 학년 |
| 100 | C413 | A | 4 |
| 100 | E412 | A | 4 |
| 200 | C123 | B | 3 |
| 300 | C312 | A | 1 |
| 300 | C324 | C | 1 |
| 400 | C123 | A | 4 |
| 400 | C312 | A | 4 |
| 400 | C324 | A | 4 |
| 400 | C413 | B | 4 |
| 400 | E412 | C | 4 |
| 500 | C312 | B | 2 |
삽입 이상: 테이블에에 데이터를 삽입할 때 의도와는 상관없이 원하지 않은 값들로 인해 삽입할 수 없게 되는 현상
ex) <수강> 테이블에서 학번이 "600"인 학생이 학년이 "2"라는 사실만을 삽입하고자 하는 경우, 삽입 이상 발생
-> <수강> 테이블의 기본키는 학번과 과목번호이기 때문에 삽입할 때 반드시 과목번호가 있어야 함
즉, 데이터가 발생되는 시점에서 과목번호가 필요 없지만 <수강> 테이블에 기록하고자 할 때 과목번호가 없어 등록할 수 없는 경우가 발생
삭제 이상: 테이블에서 한 튜플을 삭제할 때 의도와는 상관없는 값들도 함께 삭제되는, 즉 연쇄 삭제가 발생하는 현상
ex) <수강> 테이블에서 학번이 "200"인 학생이 과목번호 "C123"의 등록을 취소하고자 하는 경우 삭제 이상 발생
-> 학번이 "200"인 학생의 과목번호가 "C123"인 과목을 취소하고자 그 학생의 튜플을 삭제하면 학년 정보까지 같이 삭제된다.
과목만을 취소하고자 했지만 유지되어야 할 학년 정보까지 삭제되기 때문에 정보 손실이 발생
갱신 이상: 테이블에서 튜플에 있는 속성 값을 갱신할 때 일부 튜플의 정보만 갱신되어 정보에 불일치성이 생기는 현상
ex) <수강> 테이블에서 학번이 "400"인 학생의 학년을 "4"에서 "3"으로 변경하고자 한ㄴ 경우 갱신 이상이 발생할 수 있다.
-> 학번이 "400"인 모든 튜플의 학년 값을 갱신해야 하는데 실수로 일부 튜플만 갱신하면, 학번 "400"인 학생의 학년은 "3"과 "4",
즉 2가지 값을 가지게 되어 정보에 불일치성이 생기게 됨
함수적 종속
[어떤 테이블 R에서 X와 Y를 각각 R의 속성 집합의 부분 집합이라 하자. 속성 X의 값 각각에 대해 시간에 관계없이 항상 속성 Y의 값이 오직 하나만 연관되어 있을 때 Y는 X에 함수적 종속 또는 X가 Y를 함수적으로 결정한다고 하고, X->Y로 표기]
<학생>
| 학번 | 이름 | 학년 | 학과 |
| 400 | 이순신 | 4 | 컴퓨터공학과 |
| 422 | 유관순 | 4 | 물리학과 |
| 301 | 강감찬 | 3 | 수학과 |
| 320 | 홍길동 | 3 | 체육과 |
<학생> 테이블에서 이름, 학년, 학과는 각각 학번 속성에 함수적 종속
학번 -> 이름, 학번 -> 학년, 학번 -> 학과
학번 -> 이름, 학과, 학년
X->Y의 관계를 갖는 속성 X와 Y에서 Y를 결정자라고 하고, Y를 종속자라고 함
ex) 학번 -> 이름에서는 학번이 결정자, 이름이 종속자
ex) <수강> 테이블에서 함수적 종속을 기호로 표시하면
학번, 과목번호 -> 성적 (성적은 완전 함수적 종속)
학번 -> 학년 (학년은 부분 함수적 종속)
039(B) 정규화(Normalization)
정규화: 테이블의 속성들이 상호 종속적인 관계를 갖는 특성을 이용하여 테이블을 무손실 분해하는 과정
정규화 목적: 중복을 제거하여 삽입, 삭제, 갱신 이상의 발생 가능성을 감소
정규화 과정
<주문목록>
| 제품번호 | 제품명 | 재고수량 | 주문번호 | 고객번호 | 주소 | 주문수량 |
| 1001 | 모니터 | 2000 | A345 D347 |
100 200 |
서울 부산 |
150 300 |
| 1007 | 마우스 | 9000 | A210 A345 B230 |
300 100 200 |
광주 서울 부산 |
600 400 700 |
| 1201 | 키보드 | 2100 | D347 | 200 | 부산 | 300 |
제1정규형: 테이블 R에 속한 모든 속성의 도메인이 원자 값만으로 되어 있는 정규형
즉, 테이블의 모든 속성 값이 원자 값만으로 되어 있는 정규형
<주문목록> 테이블에서는 하나의 제품에 대해 여러 개의 주문 관련 정보(주문번호, 고객번호, 주소, 주문수량)가 발생하고 있다.
따라서 <주문목록> 테이블은 제1정규형이 아니다.
ex) <주문목록> 테이블에서 반복되는 주문 관련 정보를 분리하여 제 1정규형으로 만드시오
<제품>
| 제품번호 | 제품명 | 재고수량 |
| 1001 | 모니터 | 2000 |
| 1007 | 마우스 | 9000 |
| 1201 | 키보드 | 2100 |
<제품주문>
| 주문번호 | 제품번호 | 고객번호 | 주소 | 주문수량 |
| A345 | 1001 | 100 | 서울 | 150 |
| D347 | 1001 | 200 | 부산 | 300 |
| A210 | 1007 | 300 | 광주 | 600 |
| A345 | 1007 | 100 | 서울 | 400 |
| B230 | 1007 | 200 | 부산 | 700 |
| D347 | 1201 | 200 | 부산 | 300 |
<주문목록> 테이블에서 반복되는 주문 관련 정보인 주문번호, 고객번호, 주소, 주문수량을 분리하면 제 1정규형인 <제품> 테이블과 <제품주문> 테이블이 만들어짐
-1차 정규화 과정으로 생성된 <제품주문> 테이블의 기본키는 (주문번호, 제품번호)이고, 다음과 같은 함수적 종속 발생
| 주문번호, 제품번호 -> 고객번호, 주소, 주문수량 주문번호 -> 고객번호, 주소 고객번호 -> 주소 |
제2정규형: 테이블 R이 제 1정규형이고, 기본키가 아닌 모든 속성이 기본키에 대하여 완전 함수적 종속을 만족하는 정규형
<주문목록> 테이블이 <제품> 테이블과 <제품주문> 테이블로 무손실 분해되면서 모두 제 1정규형이 되었지만 그 중 <제품주문> 테이블에는 기본키인 (주문번호, 제품번호)에 완전 함수적 종속이 되지 않는 속성이 존재
즉 주문수량은 기본키에 대해 완전 함수적 종속이지만 고객번호와 주소는 주문번호에 의해서도 결정될 수 있으므로, 기본키에 대해 완전 함수적 종속이 아니다. 따라서 <제품주문> 테이블은 제 2정규형이 아님
ex) <제품주문> 테이블에서 주문번호에 함수적 종속이 되는 속성들을 분리하여 제 2정규형을 만드시오
<주문목록>
| 주문번호 | 제품번호 | 주문수량 |
| A345 | 1001 | 150 |
| D347 | 1001 | 300 |
| A210 | 1007 | 600 |
| A345 | 1007 | 400 |
| B230 | 1007 | 700 |
| D347 | 1201 | 300 |
<주문>
| 주문번호 | 고객번호 | 주소 |
| A345 | 100 | 서울 |
| D347 | 200 | 부산 |
| A210 | 300 | 광주 |
| B230 | 200 | 부산 |
<제품주문> 테이블에서 주문번호에 함수적 종속이 되는 속성인 고객번호와 주소를 분리(즉 부분 함수적 종속을 제거)해 내면 제 2정규형인 <주문목록> 테이블과 <주문> 테이블로 무손실 분해됨
- 제 2정규화 과정을 거쳐 생성된 <주문> 테이블의 기본키는 주문번호
그리고 <주문> 테이블에는 아직도 다음과 같은 함수적 종속들이 존재
| 주문번호 -> 고객번호, 주소 고객번호 -> 주소 |
제 3정규형: 테이블 R이 제 2정규형이고 기본키가 아닌 모든 속성이 기본키에 대해 이행적 함수적 종속을 만족하지 않는 정규형
<제품주문> 테이블이 <주문목록> 테이블과 <주문> 테이블로 무손실 분해되면서 모두 제 2정규형이 됨
그러나 <주문> 테이블에서 고객번호가 주문번호에 함수적 종속이고, 주소가 고객번홍에 함수적 종속이므로 주소는 기본키인 주문번호에 대해 이행적 함수적 종속을 만족함
즉 주문번호 -> 고객번호, 고객번호 -> 주소이므로 주문번호 -> 주소는 이행적 함수적 종속이 됨
따라서 <주문> 테이블은 제 3정규형이 아님
ex) <주문> 테이블에서 이행적 함수적 종속을 제거하여 제 3정규형을 만드시오
<주문>
| 주문번호 | 고객번호 | 주소 |
| A345 | 100 | 서울 |
| D347 | 200 | 부산 |
| A210 | 300 | 광주 |
| B230 | 200 | 부산 |
<주문>
| 주문번호 | 고객번호 |
| A345 | 100 |
| D347 | 200 |
| A210 | 300 |
| B230 | 300 |
<고객>
| 고객번호 | 주소 |
| 100 | 서울 |
| 200 | 부산 |
| 300 | 광주 |
<주문> 테이블에서 이행적 함수적 종속(즉 주문번호 -> 주소)을 제거하여 무손실 분해함으로써 제 3정규형인 <주문> 테이블과 <고객> 테이블이 생성됨
BCNF: 테이블 R에서 모든 결정자가 후보키인 정규형
- 일반적으로 제 3정규형에 후보키가 여러 개 존재하고, 이러한 후보키들이 서로 중첩되어 나타나는 경우에 적용 가능
- <수강_교육> 테이블(제 3정규형)은 함수적 종속{(학번, 과목명) -> 담당교수, (학번, 담당교수) -> 과목명, 담당교수 -> 과목명}
을 만족학 있음
<수강_교수> 테이블의 후보키는 (학번, 과목명)과 (학번, 담당교수)임
<수강_교수>
| 학번 | 과목명 | 담당교수 |
| 211746 | 데이터베이스 | 홍길동 |
| 211747 | 네트워크 | 유관순 |
| 211748 | 인공지능 | 윤봉길 |
| 211749 | 데이터베이스 | 홍길동 |
| 211747 | 데이터베이스 | 이순신 |
| 211749 | 네트워크 | 유관순 |
- <수강_교육> 테이블에서 결정자 중 후보키가 아닌 속성이 존재
즉, 함수적 종속 담당교수 -> 과목명이 존재하는데, 담당교수가 <수강_교수> 테이블에서 후보키가 아니기 때문에 <수강_교수> 테이블은 BCNF가 아님
ex) <수강_교수> 테이블에서 결정자가 후보키가 아닌 속성을 분리하여 BCNF를 만드시오.
<수강>
| 학번 | 담당교수 |
| 211746 | 홍길동 |
| 211747 | 유관순 |
| 211748 | 윤봉길 |
| 211749 | 홍길동 |
| 211747 | 이순신 |
| 211749 | 유관순 |
<교수>
| 담당교수 | 과목명 |
| 홍길동 | 데이터베이스 |
| 이순신 | 데이터베이스 |
| 윤봉길 | 인공지능 |
| 유관순 | 네트워크 |
<수강_교수> 테이블에서 BCNF를 만족하지 못하게 하는 속성(즉 담당교수 -> 과목명)을 분리해내면 위와 같이 BCNF인 <수강> 테이블과 <교수> 테이블로 무손실 분해됨
제4정규형: 테이블 R에 다중 값 종속 A->->B가 존재할 경우 R의 모든 속성이 A에 함수적 종속 관계를 만족하는 정규형
제 5정규형: 테이블 R의 모든 조인 종속이 R의 후보키를 통해서만 성립되는 정규형
정규화 과정 정리 (도부이결다조)

040(A) 반정규화(Denormalization)
반정규화(=비정규화): 정규화된 데이터 모델을 의도적으로 통합, 중복, 분리하여 정규화 원칙을 위배하는 행위
방법 4가지 - 테이블 통합, 테이블 분할, 중복 테이블 추가, 중복 속성 추가
중복 테이블 추가: 작업의 효율성 향상을 위해 테이블을 추가하는 것
(집계 테이블 추가, 진행 테이블 추가, 특정 부분만을 포함하는 테이블 추가)
041(B) 시스템 카탈로그
시스템 카탈로그: 다양한 객체에 관한 정보를 포함하는 시스템 DB
메타 데이터: 시스템 카탈로그에 저장된 정보
042(B) 트랜잭션 분석 / CRUD 분석
트랜잭션: DB의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위 또는 한꺼번에 모두 수행되어야 할 일련의 연산들
<트랜잭션의 특성>
| Atomicity(원자성) | 트랜잭션의 연산은 DB에 모두 반영되도록 완료되든지 아니면 전혀 반영되지 않도록 복구되어야 함 |
| Consistency(일관성) | 트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 DB 상태로 변환함 |
| Isolation(독립성) | 둘 이상의 트랜잭션이 동시에 병행 실행되는 경우 어느 하나의 트랜잭션 실행중에 다른 트랜잭션의 연산이 끼어들 수 X |
| Durability(영속성) | 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 함 |
CRUD 분석: 프로세스와 테이블 간에 CRUD 매트릭스를 만들어서 트랜잭션을 분석하는 것
(C>D>U>R)
트랜잭션 분석: CRUD 매트릭스를 기반으로 테이블에 발생하는 트랜잭션 양을 분석하여 테이블에 저장되는 데이터의 양을 유추하고 이를 근거를 DB의 용량 산정 및 구조의 최적화를 목적으로 함
043(C) 인덱스
044(B) 뷰/클러스터
뷰(View): 접근이 허용된 자료만을 제한적으로 보여주기 위해 하나 이상의 기본 테이블로부터 유도된, 이름을 가지는 가상 테이블
(물리적 존재 X / 정의할 때:CREATE문, 제거할 때:DROP문)
뷰의 장단점
장점 - 논리적 데이터 독립성 제공 / 단점 - 독립적인 인덱스 가질 수 X
045(B) 파티션
파티션: 대용량의 테이블이나 인덱스를 작은 논리적 단위
- 데이터 처리는 테이블 단위 / 데이터 저장은 파티션별로 수행
파티션의 종류
| 범위 분할 | 지정한 열의 값을 기준으로 분할함 |
| 해시 분할 | 해시 함수를 적용한 결과 값에 따라 데이터를 분할함 데이터를 고르게 분산할 때 유용 |
| 조합 분할 | 범위 분할로 분할한 다음 해시 함수를 적용하여 다시 분할하는 바식 파티션이 너무 커서 관리 어려울 때 유용 |
046(C) 분산 데이터베이스 설계
047(B) 데이터베이스 이중화/서버 클러스터링
RTO(목표 복구 시간): 비상사태 또는 업무 중단 시점으로부터 복구되어 가동될 때까지의 소요 시간
ex) 장애 발생 후 6시간 이내 복구 가능
RPO(목표 복구 시점): 비상사태 또는 업무 중단 시점으로부터 데이터를 복구할 수 있는 기준점
ex) 장애 발생 전인 지난 주 금요일에 백업시켜 둔 복원 시점으로 복구 가능
048(B) 데이터베이스 보안
암호화: 데이터를 보낼 때 송신자가 지정한 수신자 이외에는 그 내용을 알 수 없도록 평문을 암호문으로 변환하는 것
암호화 과정: 암호화되지 않은 평문을 암호문으로 바꾸는 과정
복호화 과정: 암호문을 원래의 평문으로 바꾸는 과정
접근통제: 데이터가 저장된 객체와 이를 사용하려는 주체 사이의 정보 흐름을 제한하는 것
(접근통제 3요소 - 정책, 메커니즘, 보안모델)
<접근통제 기술>
| 임의 접근통제(DAC) | 데이터에 접근하는 사용자의 신원에 따라 접근 권한을 부여 / 권한을 다른 사용자에게 허가 |
| 강제 접근통제(MAC) | 주체와 객체의 등급을 비교하여 접근 권한을 부여 / DB 객체별로 보안 등급 부여할 수 있음 |
| 역할기반 접근통제(RBAC) | 사용자의 역할에 따라 접근 권한을 부여 / 다중 프로그래밍 환경에 최적화 |
049(B) 데이터베이스 백업
DB 백업: 전산 장비의 장애에 대비하여 데이터를 보호, 복구하기 위한 작업
로그 파일: DB의 처리 내용이나 이용 상황 등 상태 변화를 시간의 흐름에 따라 모두 기록한 파일
(UNDO: 과거 상태로 복귀 / REDO: 현재 상태로 재생)
050(B) 스토리지
DAS(Direct Attached Storage): 서버와 저장장치를 전용 케이블로 직접 연결하는 방식
051(D) 논리 데이터 모델의 변환
052(A) 자료 구조
자료 구조: 자료를 기억장치의 공간 내에 저장하는 방법과 자료 간의 관계, 처리 방법 등을 연구 분석하는 것

스택(Stack): 리스트의 한쪽 끝으로만 자료의 삽입, 삭제 작업이 이루어지는 자료 구조
- 후입선출(LIFO) 방식
- 저장할 기억 공간 없는 상태에서 데이터 삽입 시 -> 오버플로
- 삭제할 데이터 없는 상태에서 데이터 삭제 시 -> 언더플로

큐(Queue): 리스트의 한쪽에서는 삽입 작업, 다른 한쪽에서는 삭제 작업이 이루어지는 자료 구조
- 선입선출(FIFO) 방식
- 시작을 표시하는 프런트(Front) 포인트, 끝을 표시하는 리어(Rear) 포인터

방향/무방향 그래프의 최대 간선 수
방향 그래프의 최대 간선 수: n(n-1)
무방향 그래프에서 최대 간선 수: n(n-1)/2
n은 정점 개수
053(C) 트리(Tree)
054(A) 이진 트리(Tree)
이진 트리: 차수(Degree)가 2 이하인 노드들로 구성된 트리, 즉 자식이 둘 이하인 노드들로만 구성된 트리
<트리의 운행법>
Preorder 운행법: Root -> Left -> Right
Inorder 운행법: Left -> Root -> Right
Postorder 운행법: Left -> Right -> Root
<수식의 표기법>
전위 표기법(PreFix): 연산자 -> Left -> Right, +AB
중위 표기법(InFix): Left -> 연산자 -> Right, A+B
후위 표기법(PostFix): Left -> Right -> 연산자, AB+
055(A) 정렬(Sort)
삽입 정렬: 이미 순서화된 파일에 새로운 하나의 레코드를 순서에 맞게 삽입시켜 정렬하는 방식
- 시간 복잡도: O(n2)

선택 정렬: n개의 레코드 중에서 최소값을 찾아 첫 번째 레코드 위치에 놓고, 나머지 (n-1)개 중에서 다시 최소값을 찾아 두 번째 레코드 위치에 놓는 방식을 반복하여 정렬하는 방식
- 평균, 최악 시간 복잡도: O(n2)

버블 정렬: 인접한 두 개의 레코드 키 값을 비교하여 그 크기에 따라 레코드 위치를 서로 교환하는 정렬 방식
- 평균, 최악 시간 복잡도: O(n2)
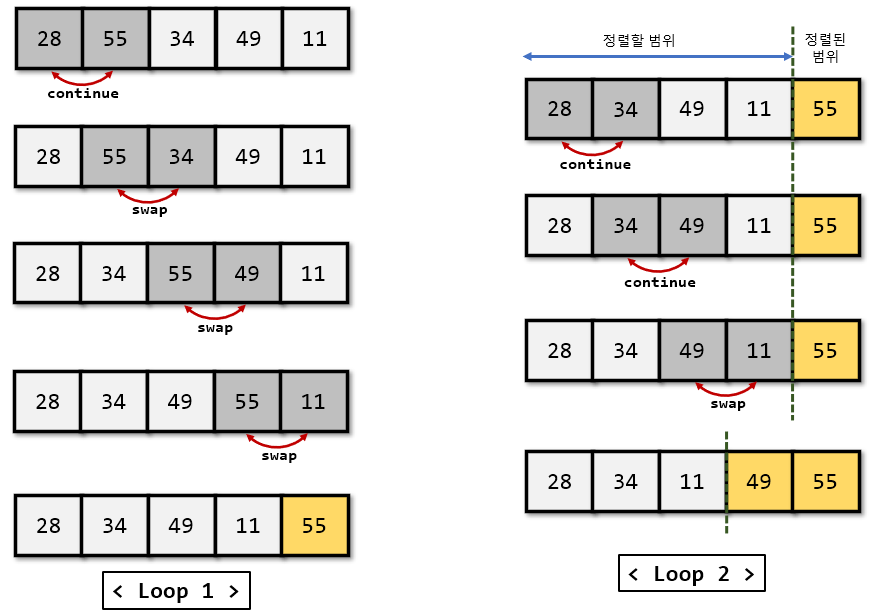
퀵 정렬: 키를 기준으로 작은 값은 왼쪽, 큰 값은 오른쪽 서브 파일에 분해시키는 과정을 반복하는 정렬 방식
- 평균 시간 복잡도: O(nlog2n) / 최악 시간 복잡도: O(n2)
힙 정렬: 완전 이진 트리를 이용한 정렬 방식
- 평균, 최악 시간 복잡도: O(nlog2n)
2-Way 합병 정렬: 이미 정렬되어 있는 두 개의 파일을 한 개의 파일로 합병하는 정렬 방식
- 평균, 최악 시간 복잡도: O(nlog2n)
'정보처리기사' 카테고리의 다른 글
| [실기] 6장. 화면 설계 (0) | 2025.10.10 |
|---|---|
| [실기] 5장. 인터페이스 구현 (0) | 2025.10.10 |
| [실기] 4장. 서버 프로그램 구현 (0) | 2025.10.09 |
| [실기] 3장. 통합 구현 (0) | 2025.10.09 |
| [실기] 1장. 요구사항 확인 (0) | 2025.09.30 |

