
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- colab
- rnn
- OSS
- 국가과제
- VSCode
- LINUX MASTER
- Github
- Rocky Linux
- C언어
- Web
- Spring Boot
- Resnet
- 코딩도장
- Powershell
- GoogleDrive
- API
- 인터넷의이해
- git
- Spring
- Database
- 고등학생 대상
- cloud
- Docker
- ICT멘토링
- KAKAO
- 크롤링 개발
- suricata
- Python
- ChatGPT
- Machine Learning
Archives
- Today
- Total
코딩두의 포트폴리오
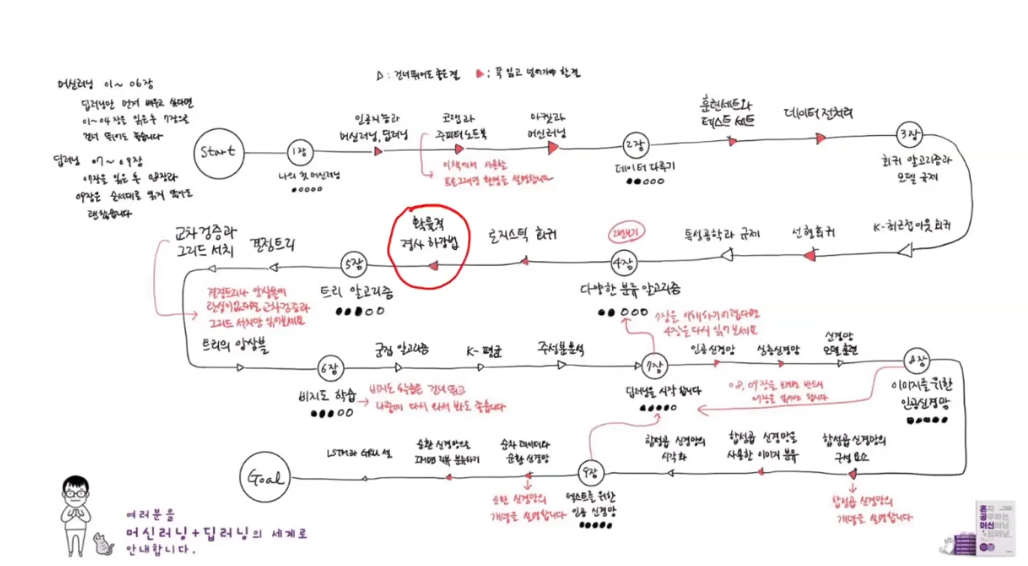
확률적 경사 하강법 본문
가상의 시나리오

데이터 추가 시 새로운 모델을 생성
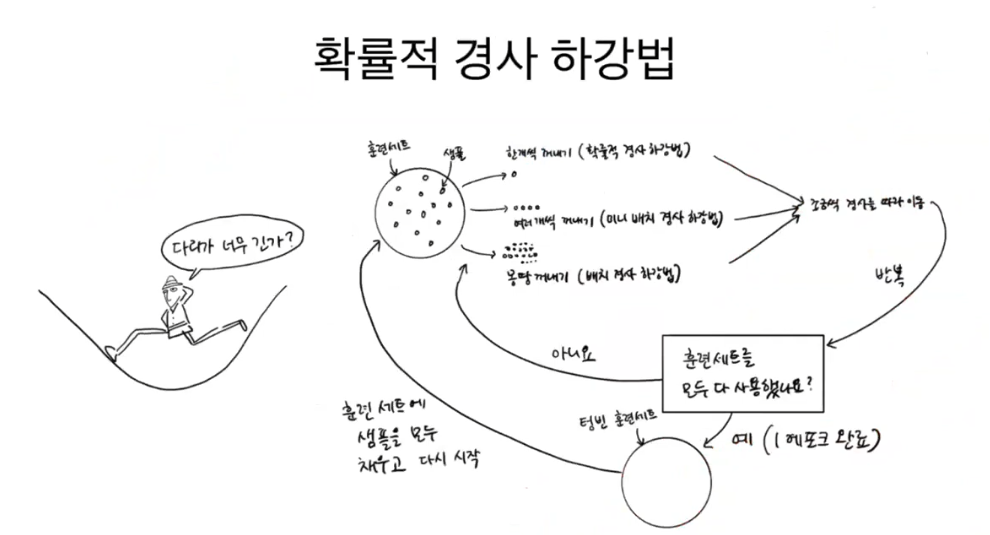
확률적 경사 하강법(Stochastic Gradient Descent)은 랜덤 방식
비용 함수를 최소화하기 위해 사용
확률적 경사 하강법은 조금씩 내려가는 방식
epoch = 전체 훈련 데이터셋을 한 번 모델에 전달하여 학습하는 단계
-> 여러 에포크를 통해 모델이 데이터를 반복적으로 학습 -> 가중치가 최적화
손실 함수는 나쁜 정도를 측정하는 함수

모델의 예측 값과 실제 값 간의 차이를 측정
모델의 성능을 최적화하는데 사용
정확도는 손실 함수로 사용할 수 X (= 미분 가능 X)
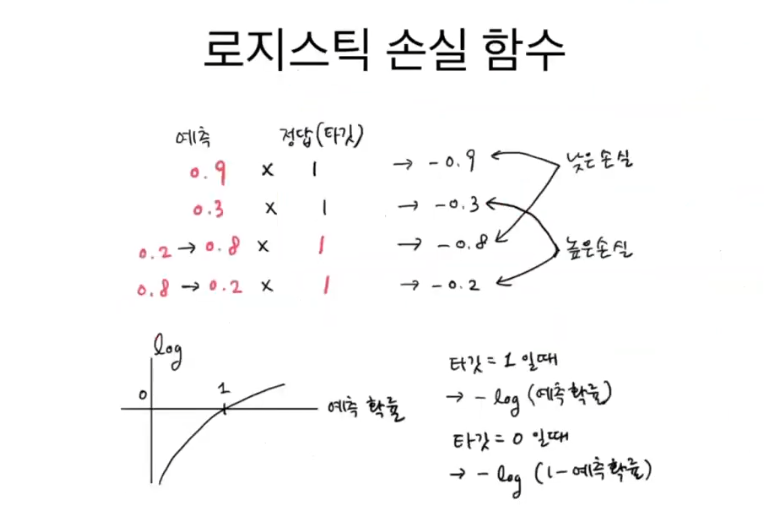
분류일 때 로지스틱 손실 함수 사용 (이진 분류 모델에서 사용되는 손실 함수)
회귀 - 평균 절댓값 오차, 평균 절댓값 오차 -> 미분 가능하여 손실 함수로 사용 가능
분류 - 정확도로 모델의 성능을 확인
정답에 가까운 것은 낮은 값 / 정답과 먼 값은 높은 값
손실 계산 시 양수로 변경 좀 더 편함
전처리

경사하강법 사용 시 특성의 스케일을 꼭 조정해야 함
분류 문제 시

정확도 출력
테스트 셋의 값이 작기 때문에 훈련이 덜 된 과소적합 (0.775)
epoch를 늘려 반복해서 과대적합으로 만들어야 함 (0.825)
- 모델 생성: SGDClassifier를 로지스틱 회귀(loss='log')와 함께 설정
- 모델 학습: fit 메소드를 사용하여 훈련 데이터로 모델을 학습
- 정확도 평가: 훈련 데이터와 테스트 데이터에 대한 모델의 정확도를 출력
- 부분 학습: partial_fit 메소드를 사용하여 모델을 추가 학습
- 재평가: 부분 학습 후 모델의 정확도를 다시 출력
과대적합 vs 과소적합

- 과소적합: 모델이 충분히 학습되지 않아 훈련 세트와 테스트 세트 모두에서 성능이 낮음
- 과대적합: 모델이 훈련 세트에 지나치게 맞추어져 테스트 세트에서 성능이 저하됨
- 적절한 에포크 수: 과소적합과 과대적합 사이의 적절한 균형을 찾는 것이 중요. 이 지점에서 모델은 훈련 세트와 테스트 세트에서 모두 좋은 성능을 보임
조기 종료

- 조기 종료: 조기 종료는 모델이 과적합되기 전에 학습을 중단하는 기법
- 반복 학습: partial_fit을 사용하여 여러 번 학습하고 각 에포크마다 성능을 기록
- 결과 시각화: 에포크에 따른 성능 변화를 그래프로 확인하여 적절한 에포크 수를 선택
- 최종 학습: 선택된 에포크 수를 기준으로 최종 모델을 학습하고 성능을 평가
100정도의 에포크가 적절한 절충점
확률적 경사 하강법을 사용하는 이유
- 빠른 학습: 각 반복(iteration)에서 하나의 샘플을 사용하여 모델 파라미터를 업데이트하므로, 계산이 빠르고 큰 데이터셋에서도 효율적
- 적은 메모리 사용: 한 번에 하나의 샘플만 메모리에 적재하여 처리하므로 메모리 사용량이 적음
- 실시간 학습 가능: 새로운 데이터가 들어올 때마다 즉시 모델을 업데이트할 수 있어 실시간 학습에 적합
- 지역 최소값에서 탈출 가능성: 작은 배치나 단일 샘플을 사용하므로 비용 함수의 복잡한 표면에서 지역 최소값에서 탈출할 가능성이 높음
- 빨리 수렴: 초기 단계에서 빠르게 수렴하여 모델 성능을 빠르게 개선
'AI/머신러닝 + 딥러닝' Related Articles
more



